Zrozumienie Document Object Model (DOM) jest absolutnie fundamentalne dla każdego, kto stawia pierwsze kroki w świecie tworzenia stron internetowych. To właśnie DOM stanowi pomost między statycznym kodem HTML a dynamiczną, interaktywną stroną, którą użytkownik widzi w przeglądarce. Bez niego nie bylibyśmy w stanie ożywić naszych projektów, sprawić, by reagowały na działania użytkownika czy płynnie zmieniały swoją zawartość.
DOM to dynamiczna reprezentacja Twojej strony, klucz do interaktywności w przeglądarce
- Document Object Model (DOM) to obiektowa reprezentacja dokumentu HTML w pamięci przeglądarki, tworzona automatycznie po wczytaniu strony.
- Umożliwia on językom skryptowym, takim jak JavaScript, dostęp do struktury, treści i stylów strony oraz ich modyfikację w czasie rzeczywistym.
- DOM ma hierarchiczną strukturę drzewa, gdzie każdy element HTML, atrybut i tekst to węzeł.
- Różni się od statycznego kodu HTML tym, że jest żywą, modyfikowalną wersją strony widoczną dla programisty.
- Zrozumienie DOM jest niezbędne do tworzenia dynamicznych i responsywnych interfejsów użytkownika.
Czym jest DOM i dlaczego każdy początkujący programista musi go zrozumieć?
Document Object Model (DOM) to nic innego jak niezależny od platformy i języka interfejs programistyczny (API), który reprezentuje dokument HTML, XHTML lub XML jako strukturę drzewa. Kiedy przeglądarka wczytuje Twoją stronę, automatycznie tworzy w swojej pamięci tę obiektową reprezentację. Dzięki temu, języki skryptowe a przede wszystkim JavaScript zyskują możliwość dynamicznego dostępu do każdego elementu na stronie, modyfikowania jego zawartości, struktury, a nawet stylów CSS w czasie rzeczywistym. Dla początkującego programisty zrozumienie DOM jest absolutnie kluczowe, ponieważ to właśnie ono otwiera drzwi do tworzenia interaktywnych formularzy, dynamicznych galerii zdjęć, animacji czy jednoplikowych aplikacji (SPA). Bez tej wiedzy Twoje strony pozostaną statyczne i bierne.
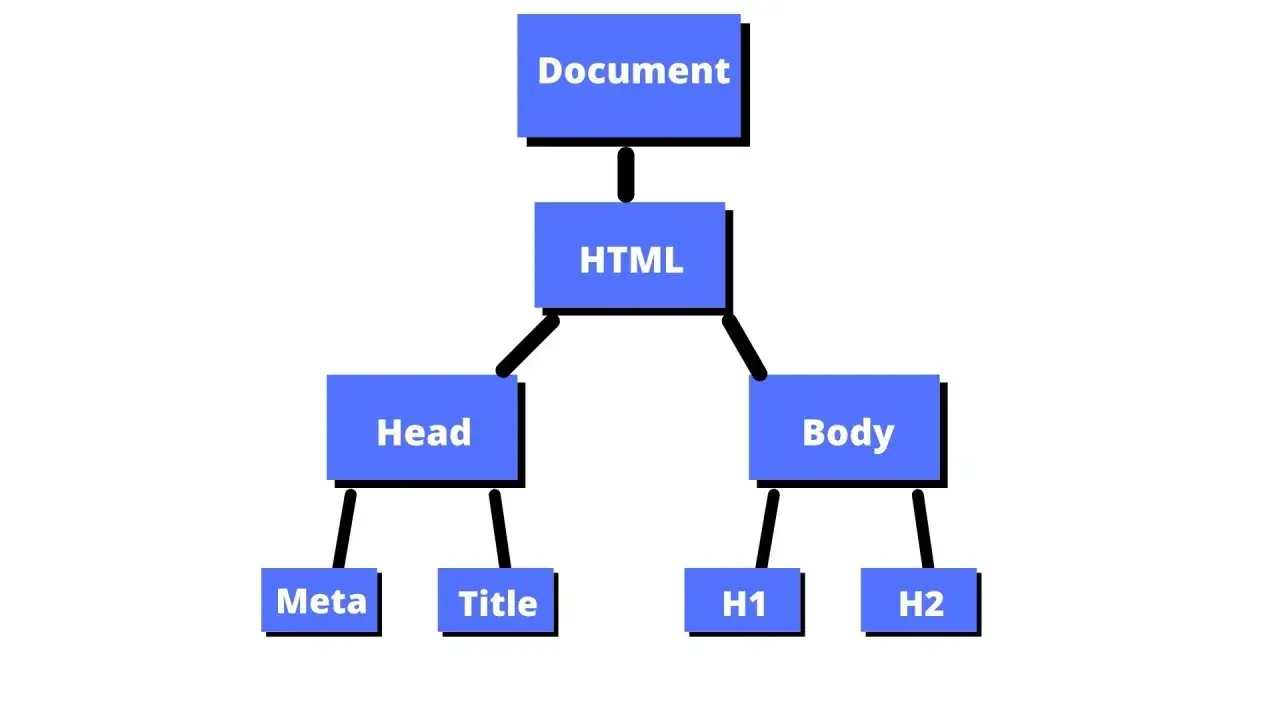
Jak przeglądarka interpretuje Twój kod HTML?
Krok po kroku: Co dzieje się po wpisaniu adresu w przeglądarce?
Zastanawiałeś się kiedyś, co dokładnie dzieje się od momentu, gdy wpiszesz adres strony w przeglądarce, aż do chwili, gdy zobaczysz gotową witrynę? To fascynujący proces, w którym DOM odgrywa centralną rolę. Oto uproszczony schemat:
- Wpisanie URL i żądanie: Wpisujesz adres strony (URL) i naciskasz Enter. Przeglądarka wysyła żądanie do serwera, aby pobrać pliki strony.
- Pobieranie zasobów: Serwer odpowiada, wysyłając pliki HTML, CSS, JavaScript, obrazy itp.
- Parsowanie HTML: Przeglądarka zaczyna czytać (parsuje) plik HTML linia po linii. W tym procesie tworzy tokeny dla każdego tagu, atrybutu i tekstu.
-
Budowanie drzewa DOM: Na podstawie tych tokenów przeglądarka konstruuje w pamięci obiektową reprezentację dokumentu czyli właśnie drzewo DOM. Każdy element HTML (np. ,
) staje się węzłem w tym drzewie.- Parsowanie CSS i budowanie CSSOM: Równolegle, przeglądarka parsuje pliki CSS i tworzy kolejne drzewo CSS Object Model (CSSOM), które reprezentuje wszystkie style.
- Tworzenie drzewa renderowania: DOM i CSSOM są łączone, tworząc drzewo renderowania (Render Tree), które zawiera tylko te elementy, które będą widoczne na stronie, wraz z ich obliczonymi stylami.
- Układ (Layout/Reflow): Przeglądarka oblicza dokładne pozycje i rozmiary każdego elementu na stronie.
- Malowanie (Paint): Wreszcie, przeglądarka "maluje" piksele na ekranie, wyświetlając stronę użytkownikowi.
HTML a DOM: Jaka jest kluczowa różnica i dlaczego ma to znaczenie?
Często widzę, że początkujący programiści mylą kod źródłowy HTML z DOM. Pozwól, że to wyjaśnię. Kod źródłowy HTML to statyczny tekst, który napisałeś w edytorze i który przeglądarka pobiera z serwera. To tak, jakbyś miał przepis na ciasto jest to zbiór instrukcji, niezmienny dokument. DOM natomiast to żywa, dynamiczna reprezentacja tego przepisu w pamięci przeglądarki. To już nie przepis, a gotowe ciasto, które możesz kroić, dekorować, a nawet zmieniać składniki w locie. Kiedy JavaScript wchodzi do gry, to właśnie on "operuje" na tym "cieście", czyli na DOM-ie, a nie na oryginalnym przepisie HTML. Możesz dodawać nowe elementy, usuwać istniejące, zmieniać tekst, obrazy, a nawet całe sekcje strony, nie zmieniając ani jednej linii w oryginalnym pliku HTML. To, co widzisz w narzędziach deweloperskich przeglądarki w zakładce "Elements", to właśnie aktualny stan drzewa DOM, a niekoniecznie oryginalny kod HTML. Ta dynamiczna natura jest kluczowa dla tworzenia nowoczesnych, interaktywnych doświadczeń użytkownika.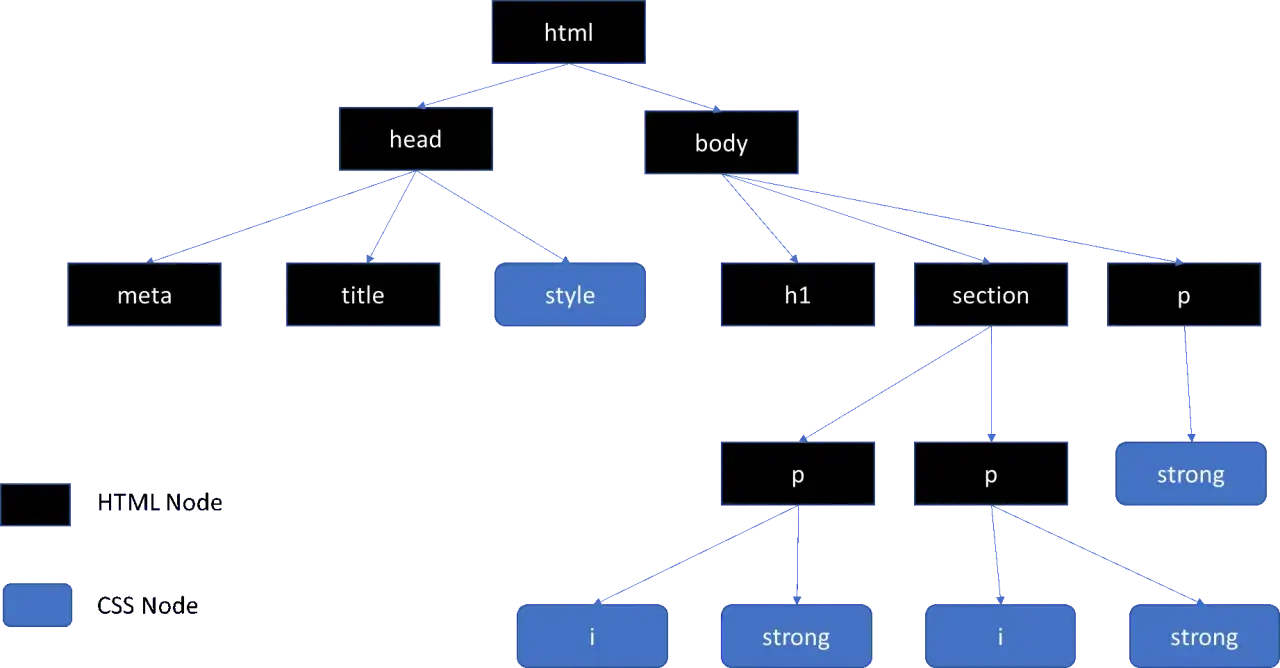
Drzewo genealogiczne Twojej strony, czyli wizualizacja struktury DOM
Aby lepiej zrozumieć strukturę DOM, pomyśl o niej jak o drzewie genealogicznym Twojej strony internetowej. Na samym szczycie tego drzewa, jako "przodek" wszystkich elementów, znajduje się obiektdocument. To on jest korzeniem całego drzewa i reprezentuje całą stronę HTML. Poniżej obiektudocumentznajdziesz element, który jest jego bezpośrednim dzieckiem. Następnie, wewnątrz, mamy dwoje "dzieci":i, które są dla siebie "rodzeństwem". Wewnątrzmogą znajdować się kolejne elementy, takie jak,,class="moj-styl") oraz każdy fragment tekstu (np. "Witaj świecie!") to oddzielny "węzeł" (node) w tym drzewie. Te węzły są ze sobą powiązane precyzyjnymi relacjami: rodzic-dziecko-rodzeństwo. Dzięki tej hierarchicznej strukturze JavaScript może łatwo nawigować po stronie, odnajdywać konkretne elementy i manipulować nimi.Z czego składa się drzewo DOM? Poznaj jego anatomię
Główny pień: Czym jest obiekt `document`?
Jak już wspomniałem, obiektdocumentjest absolutnym korzeniem i głównym punktem wejścia do całego drzewa DOM. Reprezentuje on całą stronę HTML załadowaną w przeglądarce. Kiedy zaczynasz pisać kod JavaScript, który ma wchodzić w interakcję ze stroną, niemal zawsze zaczynasz od obiektudocument. To właśnie z niego wywołujesz metody do znajdowania elementów, tworzenia nowych czy nasłuchiwania na zdarzenia. Bez obiektudocumentnie miałbyś dostępu do żadnej części swojej strony.Gałęzie i liście: Węzły elementów, atrybutów i tekstu
Drzewo DOM składa się z różnych typów węzłów, z których każdy pełni określoną funkcję. Zrozumienie ich jest kluczowe do efektywnej manipulacji.-
Węzeł dokumentu (Document Node): To korzeń całego drzewa, reprezentowany przez obiekt
document. Jest nadrzędny dla wszystkich innych węzłów. -
Węzeł elementu (Element Node): Reprezentuje każdy tag HTML, taki jak ,
,,. Są to "budulce" Twojej strony, które mogą zawierać inne elementy, tekst czy atrybuty.- Węzeł tekstowy (Text Node): Zawiera czysty tekst, który znajduje się wewnątrz elementów HTML. Na przykład, tekst "Witaj świecie!" wewnątrz
Witaj świecie!
- Węzeł atrybutu (Attribute Node): Reprezentuje atrybuty elementów, takie jak
id,class,src,href. Choć technicznie są częścią elementów, DOM traktuje je jako oddzielne węzły, do których można mieć dostęp.- Węzeł komentarza (Comment Node): Reprezentuje komentarze w kodzie HTML (
). Choć niewidoczne dla użytkownika, są częścią struktury DOM.Relacje rodzinne w DOM: Rodzice, dzieci i rodzeństwo w kodzie
Relacje między węzłami w DOM są bardzo intuicyjne i przypominają więzi rodzinne. Każdy węzeł, z wyjątkiem korzenia, ma jednego rodzica (parent). Elementy, które znajdują się bezpośrednio wewnątrz innego elementu, są jego dziećmi (children). Na przykład,isą dziećmi elementu. Z kolei węzły, które mają tego samego rodzica, są dla siebie rodzeństwem (siblings). Zrozumienie tych relacji jest absolutnie kluczowe, ponieważ JavaScript oferuje szereg właściwości i metod, które pozwalają na nawigowanie po tym drzewie. Możesz łatwo znaleźć rodzica danego elementu (element.parentNode), jego pierwsze lub ostatnie dziecko (element.firstChild,element.lastChild), a także przejść do poprzedniego lub następnego elementu rodzeństwa (element.previousElementSibling,element.nextElementSibling). To potężne narzędzia do precyzyjnego lokalizowania i modyfikowania elementów na stronie.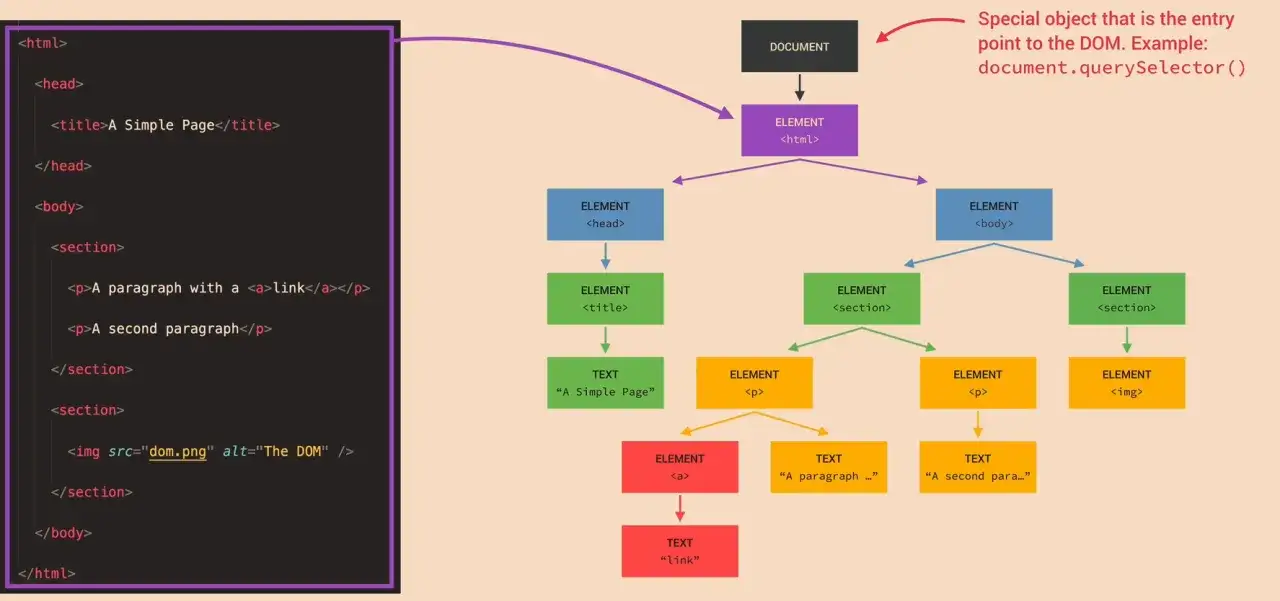
Ożyw swoją stronę: Jak JavaScript manipuluje DOM-em?
To właśnie tutaj zaczyna się prawdziwa magia! JavaScript jest językiem, który pozwala nam w pełni wykorzystać potencjał DOM, przekształcając statyczną stronę w dynamiczne i interaktywne doświadczenie. Pokażę Ci kilka podstawowych, ale niezwykle potężnych technik.Znajdowanie elementów: Jak "złapać" konkretny element na stronie? (querySelector, getElementById)
Zanim będziesz mógł coś zmienić na stronie, musisz najpierw "złapać" konkretny element. JavaScript oferuje kilka metod do tego celu:-
document.getElementById('identyfikator'): To najszybsza metoda, jeśli znasz unikalny identyfikator (atrybutid) elementu.const mojDiv = document.getElementById('glowny-kontener'); -
document.getElementsByClassName('nazwa-klasy'): Zwraca kolekcję wszystkich elementów, które mają daną klasę. Pamiętaj, że zwraca "żywą" kolekcję (HTMLCollection), nawet jeśli znajdzie tylko jeden element.const przyciski = document.getElementsByClassName('przycisk'); -
document.querySelector('selektor-css'): To nowsza i niezwykle elastyczna metoda. Pozwala używać dowolnych selektorów CSS (takich jak#id,.klasa,tag,tag[atrybut="wartosc"]) i zwraca pierwszy pasujący element.const pierwszyParagraf = document.querySelector('p'); const elementPoId = document.querySelector('#moj-id'); const elementPoKlasie = document.querySelector('.moja-klasa'); -
document.querySelectorAll('selektor-css'): Podobnie jakquerySelector, ale zwraca wszystkie pasujące elementy jako statyczną listę węzłów (NodeList).const wszystkieParagrafy = document.querySelectorAll('p'); const wszystkiePrzyciski = document.querySelectorAll('button.aktywny');
Dynamiczna zmiana treści: Modyfikowanie tekstu i HTML (textContent vs innerHTML)
Po znalezieniu elementu możesz zmienić jego zawartość. Mamy do dyspozycji dwie główne właściwości:-
element.textContent: Zmienia lub pobiera tylko tekstową zawartość elementu. Jest bezpieczniejszy, ponieważ nie interpretuje żadnego kodu HTML jako znaczników, traktując go jako zwykły tekst.const naglowek = document.querySelector('h1'); naglowek.textContent = 'Nowy tytuł strony'; // Zmienia tekst console.log(naglowek.textContent); // Pobiera tekst -
element.innerHTML: Zmienia lub pobiera całą zawartość HTML wewnątrz elementu. Pozwala na wstawienie znaczników HTML, co jest bardzo potężne, ale wymaga ostrożności, ponieważ może prowadzić do luk bezpieczeństwa (np. ataków XSS), jeśli wstawiasz niezaufane dane.const kontener = document.getElementById('kontener'); kontener.innerHTML = 'Ten tekst zawiera pogrubienie.
'; // Wstawia HTML console.log(kontener.innerHTML); // Pobiera HTML
Zmiana wyglądu w locie: Jak zarządzać stylami i klasami CSS?
JavaScript pozwala również na dynamiczne wpływanie na wygląd elementów:-
Bezpośrednia zmiana stylów (
element.style): Możesz bezpośrednio modyfikować właściwości CSS elementu. Pamiętaj, że nazwy właściwości CSS w JavaScript są w camelCase.const mojDiv = document.getElementById('moj-div'); mojDiv.style.backgroundColor = 'blue'; mojDiv.style.fontSize = '20px'; -
Manipulowanie klasami CSS (
element.classList): To znacznie lepsza praktyka. Zamiast zmieniać pojedyncze style, dodajesz lub usuwasz klasy CSS, które definiują wygląd w pliku CSS.-
element.classList.add('nazwa-klasy'): Dodaje klasę. -
element.classList.remove('nazwa-klasy'): Usuwa klasę. -
element.classList.toggle('nazwa-klasy'): Przełącza klasę (dodaje, jeśli nie ma; usuwa, jeśli jest).
const przycisk = document.querySelector('.przycisk'); przycisk.classList.add('aktywny'); // Dodaje klasę 'aktywny' przycisk.classList.remove('domyslny'); // Usuwa klasę 'domyslny' przycisk.classList.toggle('ukryty'); // Przełącza klasę 'ukryty' -
Tworzenie i usuwanie elementów: Budowanie struktury strony w czasie rzeczywistym
JavaScript umożliwia także dynamiczne tworzenie i usuwanie elementów, co jest podstawą do budowania złożonych interfejsów:-
document.createElement('nazwa-tagu'): Tworzy nowy węzeł elementu.const nowyParagraf = document.createElement('p'); -
element.appendChild(dziecko): Dodaje węzełdzieckona koniec listy dziecielementu.nowyParagraf.textContent = 'To jest nowy paragraf.'; document.body.appendChild(nowyParagraf); // Dodaje paragraf do body -
element.insertBefore(noweDziecko, referencyjneDziecko): WstawianoweDzieckoprzedreferencyjneDziecko.const lista = document.querySelector('ul'); const nowyElementListy = document.createElement('li'); nowyElementListy.textContent = 'Nowy element na początku'; const pierwszyElement = lista.firstElementChild; lista.insertBefore(nowyElementListy, pierwszyElement); -
element.remove(): Usuwa dany element z DOM.const elementDoUsunięcia = document.getElementById('stary-div'); if (elementDoUsunięcia) { elementDoUsunięcia.remove(); }
Poza podstawami: Czym są Virtual DOM i Shadow DOM?
Zrozumienie podstaw DOM to świetny początek, ale w nowoczesnym świecie front-endu często spotkasz się z bardziej zaawansowanymi koncepcjami, które budują na DOM lub rozwiązują jego ograniczenia.Optymalizacja wydajności: Krótkie wprowadzenie do koncepcji Virtual DOM
Jednym z wyzwań związanych z bezpośrednią manipulacją DOM jest wydajność. Każda, nawet najmniejsza zmiana w rzeczywistym DOM może zmusić przeglądarkę do ponownego przeliczenia układu (reflow) i przemalowania (repaint) strony, co jest kosztowną operacją. Właśnie dlatego powstała koncepcja Virtual DOM. Virtual DOM to tak naprawdę lekka, wirtualna reprezentacja interfejsu użytkownika przechowywana w pamięci. Kiedy w aplikacji (np. napisanej w React, Vue czy Svelte) zachodzą zmiany, zamiast od razu aktualizować prawdziwy DOM, framework najpierw aktualizuje ten wirtualny odpowiednik. Następnie, specjalny algorytm porównuje aktualny Virtual DOM z jego poprzednią wersją, identyfikując tylko te fragmenty, które uległy zmianie. Dopiero wtedy, i to w jednym, zoptymalizowanym pakiecie, dokonywane są minimalne, niezbędne aktualizacje w prawdziwym DOM. To znacznie zwiększa wydajność aplikacji, zwłaszcza tych z dużą liczbą dynamicznych elementów.Przeczytaj również: Centrowanie tekstu i elementów w HTML/CSS: Opanuj to raz na zawsze!
Ukryty świat komponentów: Czym jest i do czego służy Shadow DOM?
Inną fascynującą technologią, która działa w tle, jest Shadow DOM. Jest to kluczowy element standardu Web Components i służy do enkapsulacji, czyli izolowania struktury, stylów i zachowań komponentu od reszty strony. Wyobraź sobie, że tworzysz niestandardowy komponent, na przykład złożony odtwarzacz wideo. Chcesz, aby jego wewnętrzne elementy (przyciski, suwaki, pasek postępu) miały swoje własne style i logikę, które nie będą kolidować z globalnymi stylami Twojej strony. Shadow DOM pozwala na dołączenie "ukrytego" drzewa DOM (tzw. "shadow tree") do elementu, który jest widoczny na stronie. To ukryte drzewo jest całkowicie odizolowane jego style nie wyciekają na zewnątrz, a style z zewnątrz nie wpływają na jego wnętrze. Dzięki temu możesz tworzyć wielokrotnego użytku, niezależne komponenty, które działają przewidywalnie, niezależnie od kontekstu, w którym zostaną użyte. To fundament dla budowania modularnych i skalowalnych interfejsów. - Węzeł tekstowy (Text Node): Zawiera czysty tekst, który znajduje się wewnątrz elementów HTML. Na przykład, tekst "Witaj świecie!" wewnątrz